The SD of a sample is not the same as the SD of the population
It is straightforward to calculate the standard deviation from a sample of values. But how accurate is the standard deviation? Just by chance you may have happened to obtain data that are closely bunched together, making the SD low. Or you may have happened to obtain data that are far more scattered than the overall population, making the SD high. The SD of your sample may not equal, or even be close to, the SD of the population.
The 95% CI of the SD
You can express the precision of any computed value as a 95% confidence interval (CI). It's not done often, but it is certainly possible to compute a CI for a SD. We'll discuss confidence intervals more in the next section which explains the CI of a mean. Here we are discussing the CI of a SD, which is quite different.
Interpreting the CI of the SD is straightforward. You must assume that your data were randomly and independently sampled from a Gaussian distribution. You compute the SD and its CI from that one sample, and use it to make an inference about the SD of the entire population. You can be 95% sure that the CI of the SD contains the true overall standard deviation of the population.
How wide is the CI of the SD? Of course the answer depends on sample size (N), as shown in the table below.
N |
95% CI of SD |
2 |
0.45*SD to 31.9*SD |
3 |
0.52*SD to 6.29*SD |
5 |
0.60*SD to 2.87*SD |
10 |
0.69*SD to 1.83*SD |
25 |
0.78*SD to 1.39*SD |
50 |
0.84*SD to 1.25*SD |
100 |
0.88*SD to 1.16*SD |
500 |
0.94*SD to 1.07*SD |
1000 |
0.96*SD to 1.05*SD |
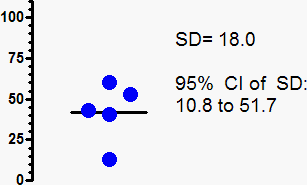
The standard deviation computed from the five values shown in the graph above is 18.0. But the true standard deviation of the population from which the values were sampled might be quite different. Since N=5, the 95% confidence interval extends from 10.8 (0.60*18.0) to 51.7 (2.87*18.0). When you compute a SD from only five values, the upper 95% confidence limit for the SD is almost five times the lower limit.
Most people are surprised that small samples define the SD so poorly. Random sampling can have a huge impact with small data sets, resulting in a calculated standard deviation quite far from the true population standard deviation.
Note that the confidence intervals are not symmetrical. Why? Since the SD is always a positive number, the lower confidence limit can't be less than zero. This means that the upper confidence interval usually extends further above the sample SD than the lower limit extends below the sample SD. With small samples, this asymmetry is quite noticeable.
If you want to compute these confidence intervals yourself, use these Excel equations (N is sample size; alpha is 0.05 for 95% confidence, 0.01 for 99% confidence, etc.):
Lower limit: =SD*SQRT((N-1)/CHIINV((alpha/2), N-1))
Upper limit: =SD*SQRT((N-1)/CHIINV(1-(alpha/2), N-1))