The field goal kicker
Let's imagine you're interested in making predictions about whether or not a football kicker will be able to make a given kick based on the distance that they'll have to kick. You know that the distance the ball has to be kicked will play an important part in determining if the kick will be good or not, so to start, you might collect some initial data on the kicker's ability from a variety of distances. To do this, you have the kicker attempt to kick one field goal from a variety of distances (we'll assume for the sake of this example that no one attempt has an impact on any other attempt). The results of this initial test might look something like the following:
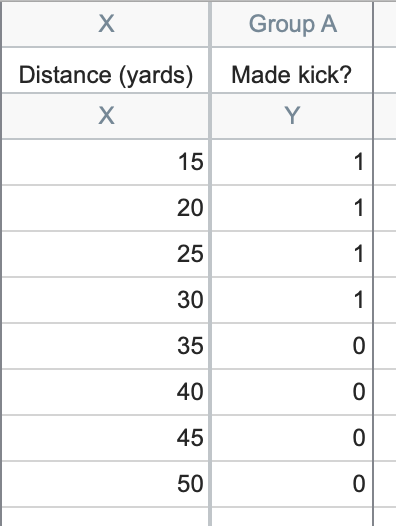
You can see that the data seem to support your hypothesis that distance plays a part in whether or not the field goal attempt will be successful: shorter kicks were successful while longer attempts were missed. In fact, you can see that all attempts over 30 yards were missed. This data represents perfect separation. When describing perfect separation on another page, it's pointed out that perfect separation isn't always necessarily a bad thing. It could simply mean that you have a variable (in this case distance) that you can use to perfectly predict the outcome (in this case whether or not the field goal attempt was successful).
But there's a problem...
In this example, it's entirely possible that our field goal kicker CAN make field goals from over 30 yards, and we simply didn't collect enough data. If we repeated this experiment, but collected results from multiple attempts at each distance (again, assuming each attempt is actually independent of the others), our data might look something like this:
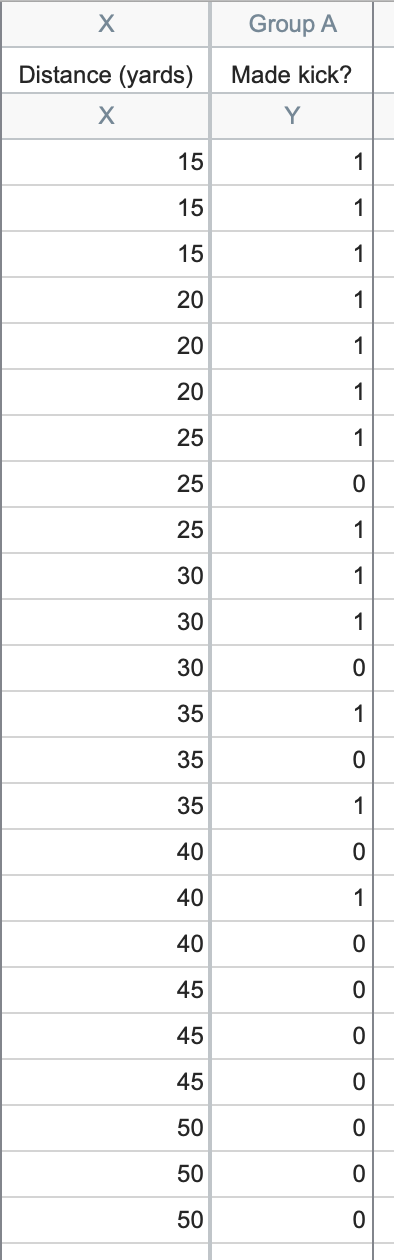
These data no longer present an issue with perfect separation, and provide us with a much better idea of how well the kicker might perform at various distances. In fact, using this data, we can determine that our kicker has even odds (1:1 odds or a probability of success = 50%) of successfully kicking a field goal at just over 34 yards (this distance is reported by Prism for this data as "X at 50%").