Similar to simple linear regression, simple logistic regression attempts to find best-fit values for a set of parameters. Unlike simple linear regression, however, simple logistic regression finds best-fit values through an iterative procedure that starts with some initial values for these parameters, and works toward the best-fit values one step at a time. Because of this, for some data sets, it’s impossible for this iterative algorithm to calculate these best-fit values. When this happens, Prism provides an error message indicating that there may be an issue with “perfect separation” in the data, or that there is only a single X value.
The mathematical concepts involved in the process to determine best-fit values (and the errors that can occur during this process) are the same for both simple and multiple logistic regression. Below, very basic explanations for why this error message might show up in simple logistic regression are provided. More detailed explanations for the model fitting process and the errors that can occur are provided on the corresponding page for multiple logistic regression.
Perfect separation
Separation is a concept that applies to data sets when the value of the X variable is a perfect predictor for the value of the Y variable. In other words, for every observation in the data set, when X is less than a certain value, Y will take on one outcome, while when X is greater than that value, Y will take on the opposite outcome. The following data represent an example of perfect separation:
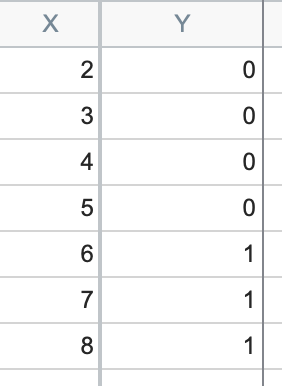
In the data set above, all Y values are 0 when X is less than or equal to 5, while all Y values are 1 when X is greater than 5. It is impossible to fit the S shaped logistic curve as the data gives no clue as what outcome to expect when X is 5.1 or 5.5 or any value between 5 and 6.
A very closely related issue occurs when data aren’t “perfectly” separated, such as in this data set:
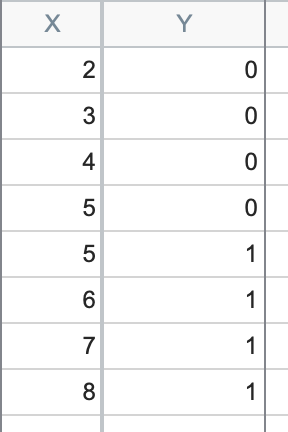
Here, you can see that for X values less than 5, Y is 0, and for X values greater than 5, Y is 1. But at X = 5, we have observations of both Y = 0 and Y = 1. This is a special case of separation called “quasi-perfect separation”.
There is only a single X value
The goal of simple logistic regression is to predict the probability of a “success” (Y = 1) given the value of the predictor (X variable). However, if all of your observations have the same value for the predictor, it’s impossible to fit a model that predicts the probability of “success” as a function of that predictor.
Mathematically, this issue is caused by linear dependence between β0 and β1. This is a problem that can also arise in multiple logistic regression when the model has multiple predictor variables.