1. Entering data for column statistics
Column statistics are most often used with data entered on data tables formatted for Column data. If you want to experiment, create a Column data table and choose the sample data set: One-way ANOVA, ordinary.
You can also choose the column statistics analysis from data entered onto XY or Grouped data tables.
2. Choose the column statistics analysis
Click  and choose Column statistics from the list of analyses for column data.
and choose Column statistics from the list of analyses for column data.
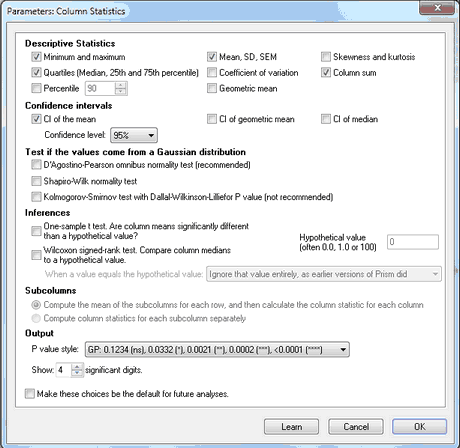
Prism's column statistics analysis computes descriptive statistics of each data set, tests for normality, and tests whether the mean of a column is different than a hypothetical value.
3. Choose analysis options
Descriptive statistics
Learn more about quartiles, median, SD, SEM, confidence interval, coefficient of variation, geometric mean, skewness and kurtosis.
Test if the values come from a Gaussian distribution
One-way ANOVA and t tests depend on the assumption that your data are sampled from populations that follow a Gaussian distribution. Prism offers three tests for normality. We suggest using the D'Agostino and Pearson test. The Kolmogorov-Smirnov test is not recommended, and the Shapiro-Wilk test is only accurate when no two values have the same value.Learn more about testing for normality.
Inferences
If you have a theoretical reason for expecting the data to be sampled from a population with a specified mean, choose the one-sample t test to test that assumption. Or choose the nonparametric Wilcoxon signed-rank test.
Subcolumns
The choices for subcolumn will not be available when you analyze data entered on table formatted for column data, which have no subcolumns. If your data are on a table formatted for XY or grouped data with subcolumns, choose to compute column statistics for each subcolumn individually or to average the subcolumns and compute columns statistics on the means.
If the data table has subcolumns for entry of mean and SD (or SEM) values, Prism calculates column statistics for the means, and ignores the SD or SEM values you entered.