Distinguish the t test analysis from the multiple t test analysis
•The t test (and nonparametric) analysis compares two data set columns. Each set of replicate values are usually entered into a column, although Prism can also enter replicates entered into side-by-side subcolumns all on one row.
•The multiple t test analysis performs many unpaired t tests at once -- one per row. Replicates are entered into side-by-side subcolumns.
•It assumes there is no pairing of values on one row. Y2 in column A is not matched to Y2 of column B.
•It also assumes no pairing or matching of values stacked in a subcolumn. The value in Column A, replicate Y2 in row 1 is not matched to the value in Column A, replicate Y2 or row 2. (Violating this assumption won't change the results.)
How to perform a multiple t test analysis with Prism
1.Create a Grouped data table. Format the table either for entry of replicate values into subcolumns, or for entry of mean, SD (or SEM) and n.
2.Enter the data on two data set columns. One unpaired t test will be performed on each row of data.
3.Click Analyze, and choose "Multiple t tests -- one per row" from the list of analyses for Grouped data.
4.Choose how to compute each test, and when to flag a comparison for further analysis.
If you want to copy/paste (or export) the P values to another table or program
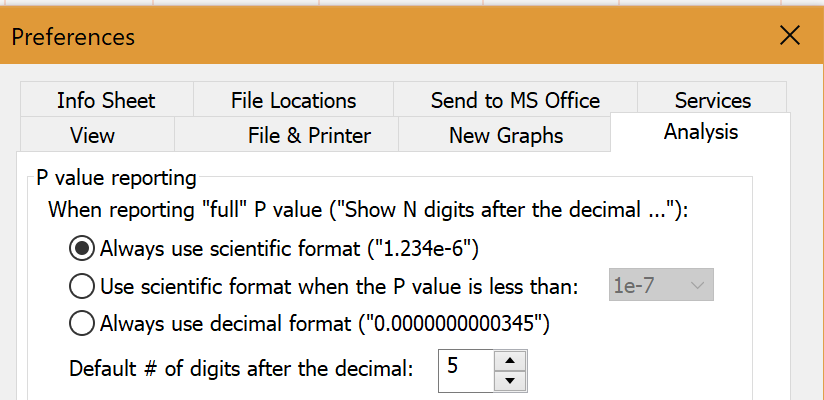
Note a potential problem when copying the P values (or adjusted P values) to another program. If any P values (or adjusted P values) show something like "<0.000001", when you copy and paste that value will be seen as text and may get ignored. To avoid this issue you need to do two things.
•In the Analysis tab of Preferences, choose either to always report P values in scientific format, or at least to report tiny P values in scientific format.
•In the parameters dialog for the multiple t test analysis, choose to report P values with N digits after the decimal and enter a large value for N.

Once you have made both of these choices, all P values will be numbers and the less than "<" symbol won't appear to confuse things.