Identifying outliers in a stack of data is simple. Click Analyze from a Column data table, and then choose Identify outliers from the list of analyses for Column data. Prism can perform outlier tests with as few as three values in a data set.
Note: This page explains how to identify an outlier from a stack of values in a data table formatted for Column data. Prism can also identify outliers during nonlinear regression.
Which method?
Prism offers three methods for identifying outliers:
ROUT
We developed the ROUT method to detect outliers while fitting a curve with nonlinear regression. Prism adapts this method to detecting outliers from a stack of values in a column data table. The ROUT method can identify one or more outliers.
Grubbs' method
Grubbs' test is probably the most popular method to identify an outlier. This method is also called the ESD method (Extreme Studentized Deviate). It can only identify one outlier in each data set. Prism uses the two-sided Grubbs' test, which means it will detect a value much larger than the rest, or a value much smaller than the rest.
Iterative Grubbs'
While it was designed to detect one outlier, Grubbs' method is often extended to detect multiple outliers. This is done using a simple method. If an outlier is found, it is removed and the remaining values are tested with Grubbs' test again. If that second test finds an outlier, then that value is removed, and the test is run a third time ...
While Grubb's test does a good job of finding one outlier in a data set, it does not work so well with multiple outliers. The presence of a second outlier in a small data set can prevent the first one from being detected. This is called masking. Grubbs' method identifies an outlier by calculating the difference between the value and the mean, and then dividing that difference by the standard deviation of all the values. When that ratio is too large, the value is defined to be an outlier. The problem is that the standard deviation is computed from all the values, including the outliers. With two outliers, the standard deviation can become large, which reduces that ratio to a value below the critical value used to define outliers. See an example of masking.
Recommendation
•If you somehow knew for sure that the data set had either no outliers or one outlier, then choose Grubbs' test.
•If you want to allow for the possibility of more than one outlier, choose the ROUT method. Compare the Grubbs' and ROUT methods.
•Avoid the iterative Grubbs' method.
•When you create a box-and-whiskers plot with Prism, you can choose to show Tukey whiskers, which shows points individually when their distance from the median exceeds 1.5 times the interquartile range (difference between the 75th and 25th percentiles). Some people define these points to be outliers We did not implement this method of outlier detection in Prism (beyond creating box-and-whiskers plots) because it seems to not be widely used, and has no real theoretical basis. Let us know if you'd like us to include this method of detecting outliers.
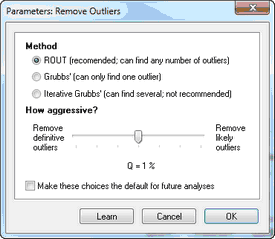
How aggressive?
There is no way to cleanly separate outliers from values sampled from a Gaussian distribution. There is always a chance that some true outliers will be missed, and that some "good points" will be falsely identified as outliers. You need to decide how aggressively to define outliers. The choice is a bit different depending on which method of outlier detection you choose.
Grubbs's test. Choose alpha.
With the Grubbs' test, you specify alpha. This has an interpretation familiar from any tests of statistical significance. If there are no outliers, alpha is the chance of mistakenly identifying an outlier.
Note that alpha applies to the entire experiment, not to each value. Assume that you set alpha to 5% and test a data set with 1000 values, all sampled from a Gaussian distribution. There is a 5% chance that the most extreme value will be identified as an outlier. That 5% applies to the entire data set, no matter how many values it has. It would be a mistake to multiply 5% by the sample size of 1000, and conclude that you'd expect 50 outliers to be identified.
Alpha is two-tailed, because the Grubbs test in Prism identifies outliers that are either "too large" or "too small".
Rout method. Choose Q.
The ROUT method is based on the False Discovery Rate (FDR), so you specify Q, which is the maximum desired FDR.
When there are no outliers (and the distribution is Gaussian), Q can be interpreted just like alpha. When all the data are sampled from a Gaussian distribution (so no outliers are present), Q is the chance of identifying one or more outliers.
When there are outliers in the data, Q is the desired maximum false discovery rate. If you set Q to 1%, then you are aiming for no more than 1% of the identified outliers to be false (are in fact just the tail of a Gaussian distribution) and thus for at least 99% identified outliers to actually be outliers (from a different distribution). If you set Q to 5%, then you are expecting no more than 5% of the identified outliers to be false and for at least 95% of the identified outliers to be real.
Recommendation
The trade-off is clear. If you set alpha or Q too high, then many of the identified "outliers" will be actually be data points sampled from the same Gaussian distribution as the others. If you set alpha or Q too low, then you won't identify all the outliers.
There are no standards for outlier identification. We suggest that you start by setting Q to 1% or alpha to 0.01.
How Prism presents the results
The results are presented on three pages:
•Cleaned data (outliers removed). You could use this page as the input to another analysis, such as a t test or one-way ANOVA.
•Outliers only.
•Summary. This page lists the number of outliers detected in each data set.