The Placement tab of the Import and Paste Special dialog lets you rearrange your data as you import/paste into Prism.
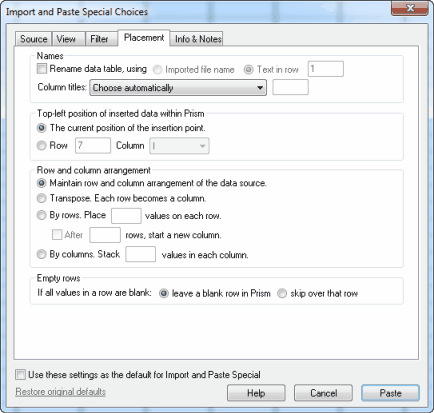
Names
The Placement tab lets you choose whether you want to rename the Prism data table and/or the Prism column titles with the name of the imported file, or with text imported from a specified row in that file.
Top-left position of inserted data within Prism
Specify the top-left corner of the data object in Prism. Normally, this will be the position of the insertion point when you choose the Import or Paste Special command, but you can change it.
Row and column arrangement
Prism can rearrange the data as it imports. If you choose Transpose, the first row in the source will become the first column in Prism, the second row in the source becomes the second column in Prism, and so on.
If the data source has one column (or row) and you want to organize the data according to your experimental design, choose By rows or By columns.
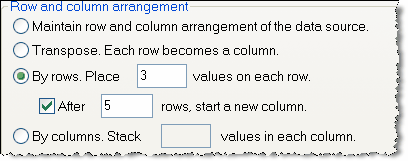
Example: Your data source has thirty values in a single column, and you wish to import into a Prism data table formatted for entry of triplicate Y values. The first three values in the source data are the first three replicates. The next three values in the source are the next set of replicates, so they belong in row 2 of data set A. After filling five rows, you want to start inserting data into data set B. Choose to import by rows, placing three values on each row and starting a new column after five rows.
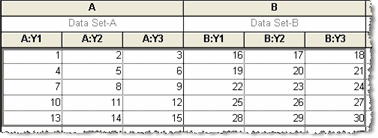
If the data source has the values from 1 to 30 in order, Prism will organize the data as shown below. When placing values side-by-side, Prism does not pay attention to the difference between subcolumns and data sets. It just puts values in the next cell to the right, and it doesn't care whether that cell is another replicate, a SD, or the beginning of a new data set. In the example above, Prism placed three values side-by-side because you entered 3 into the dialog. The data table was formatted separately for triplicate values.
|
If you choose to arrange the data “By rows” or “by columns”, Prism reads the values row-by-row from your source file, but ignores all line breaks. It treats the data as though it came from one column or one row. |
