- Prism
FEATURES
Analyze, graph and present your workComprehensive analysis and statisticsElegant graphing and visualizationsShare, view and discuss your projectsLatest product features and releasesPOPULAR USE CASES
- Enterprise
- Resources
- Support
- Pricing
JUST ADDED
Sample Size & Power Analysis
Explore relationships between Power, Sample Size, and Effect Size. Now part of Prism Cloud.

Explore the relationship between Power,
Sample Size and Effect Size
Sample Size and Effect Size
Fully adjustable parameters to calculate key values. Determine the sample size needed to detect a predicted effect size, or find the smallest detectable effect size when working with a limited sample size.
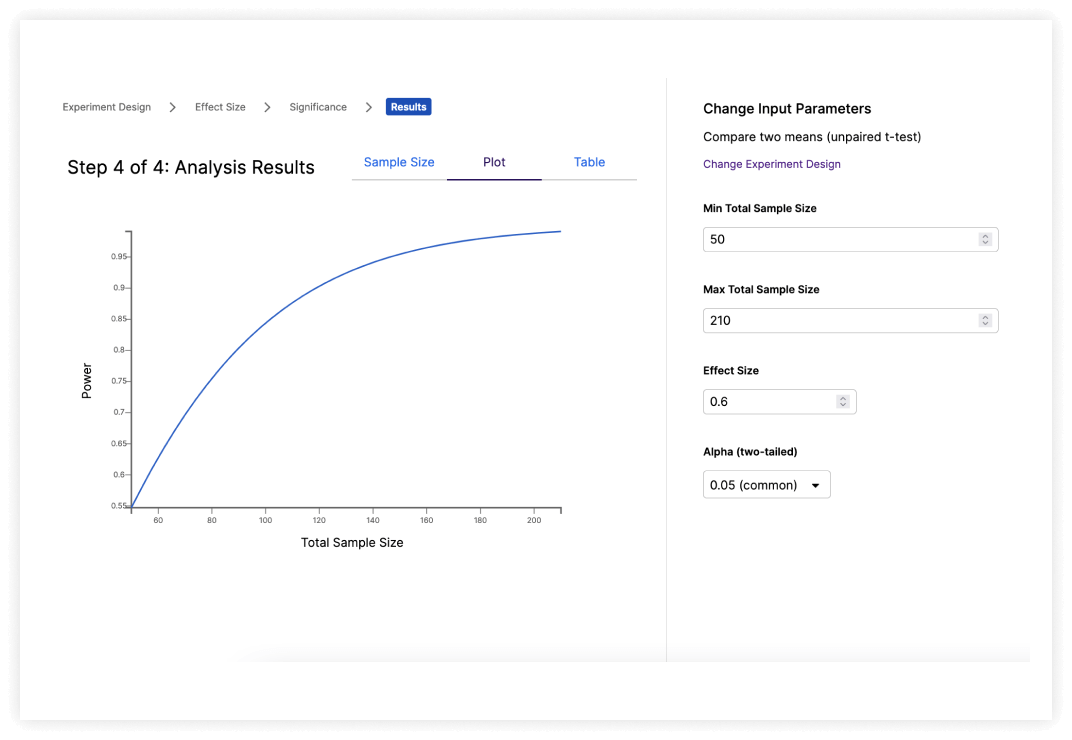
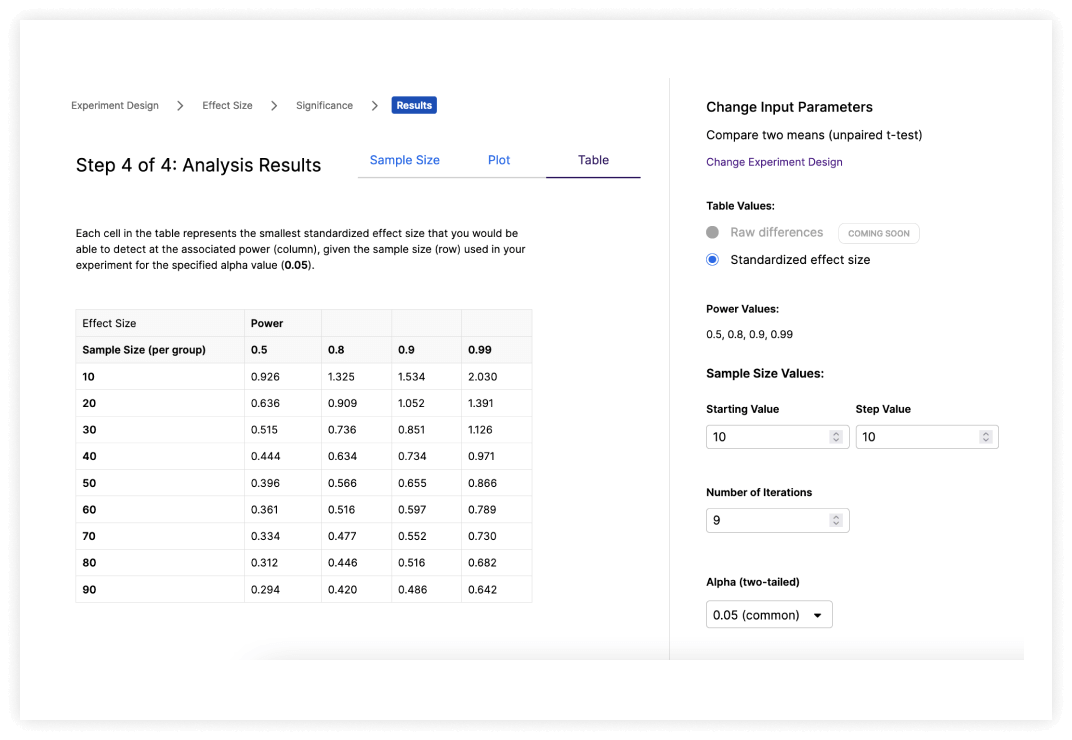
Perform Power Analysis Easily
Walk through the analysis using detailed, intuitive explanations, or jump in with a default set of adjustable parameters
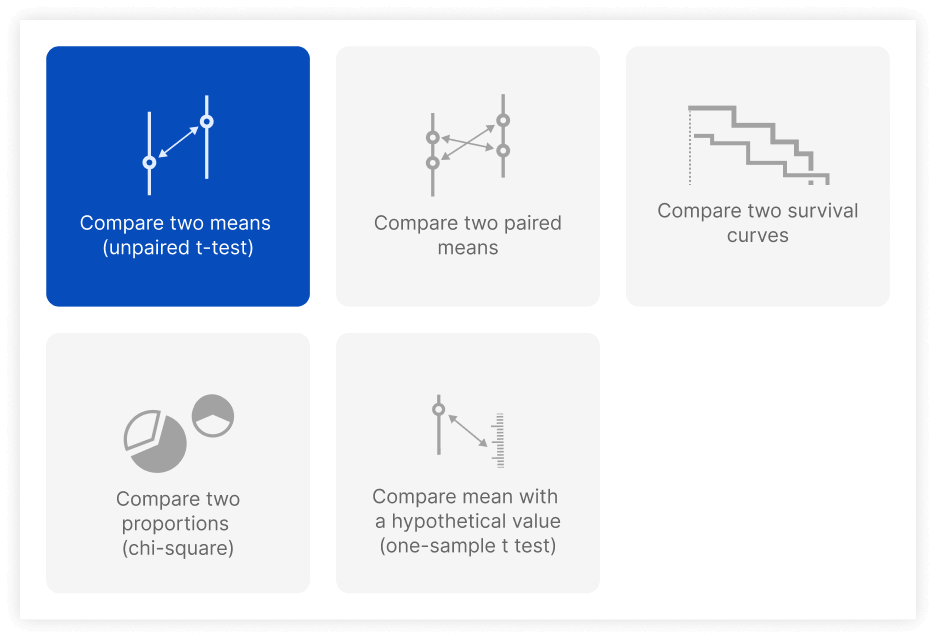

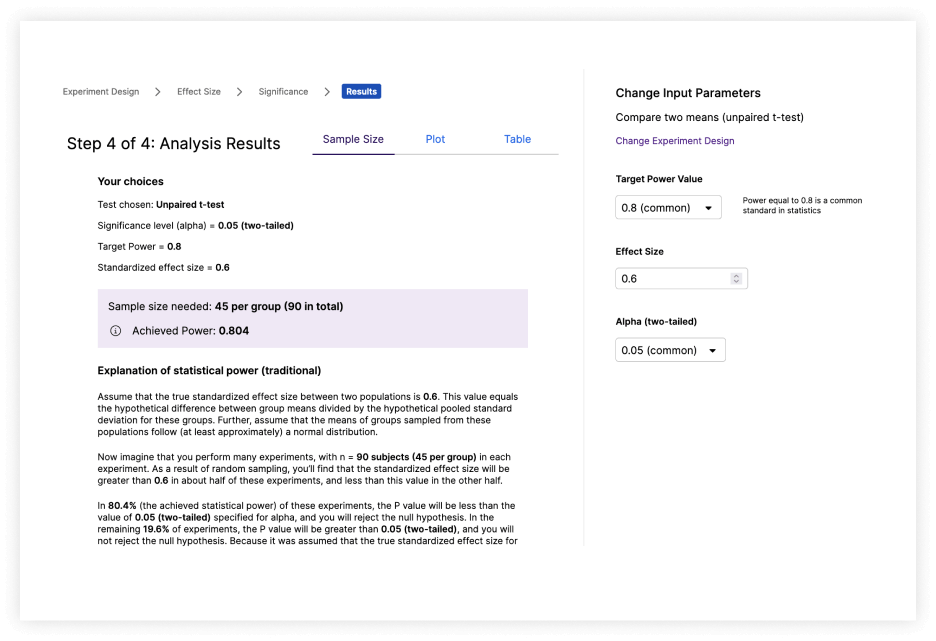
Power Analysis Highlights
Highlights:
- Multiple experimental designs to choose from
- Fast and interactive data exploration and graphing
- Simple and clear explanations of all statistical terms and choices
- Intuitive interfaces suitable for both newcomers and biostatisticians
Maximize the impact of your research with our advanced Power and Sample Size Analysis feature. Designed specifically for scientists, it ensures you achieve statistically significant results without unnecessary resource expenditure.
Optimize your experiments from the start by accurately determining the ideal sample size needed to detect true effects. Streamline your research process, conserve valuable resources, and boost the reliability of your findings—all within one platform. Make every study count with precision planning and analysis.
Start Free 30 Day Trial
No credit card required.